
You can only build safe ASI if ASI is globally banned
If you can build safe ASI, you could have built unsafe ASI long ago

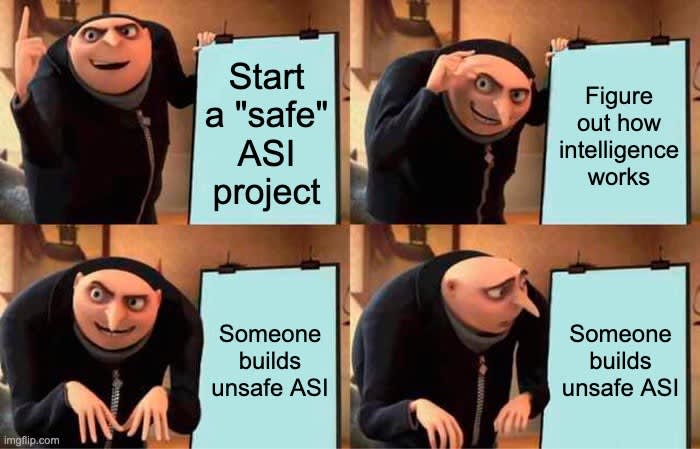
Sometimes people make various suggestions that we should simply build “safe” artificial Superintelligence (ASI), rather than the presumably “unsafe” kind.1
There are various flavors of “safe” people suggest.
Sometimes they suggest building “aligned” ASI: You have a full agentic autonomous god-like ASI running around, but it really really loves you and definitely will do the right thing.
Sometimes they suggest we should simply build “tool AI” or “non-agentic” AI.
Sometimes they have even more exotic, or more obviously-stupid ideas.
Now I could argue at lengths about why this is astronomically harder than people think it is, why their various proposals are almost universally unworkable, why even attempting this is insanely immoral2, but that’s not the main point I want to make.
Instead, I want to make a simpler point:
Assume you have a research agenda that, if executed, results in a ASI-tier powerful software system that you can “control”.3
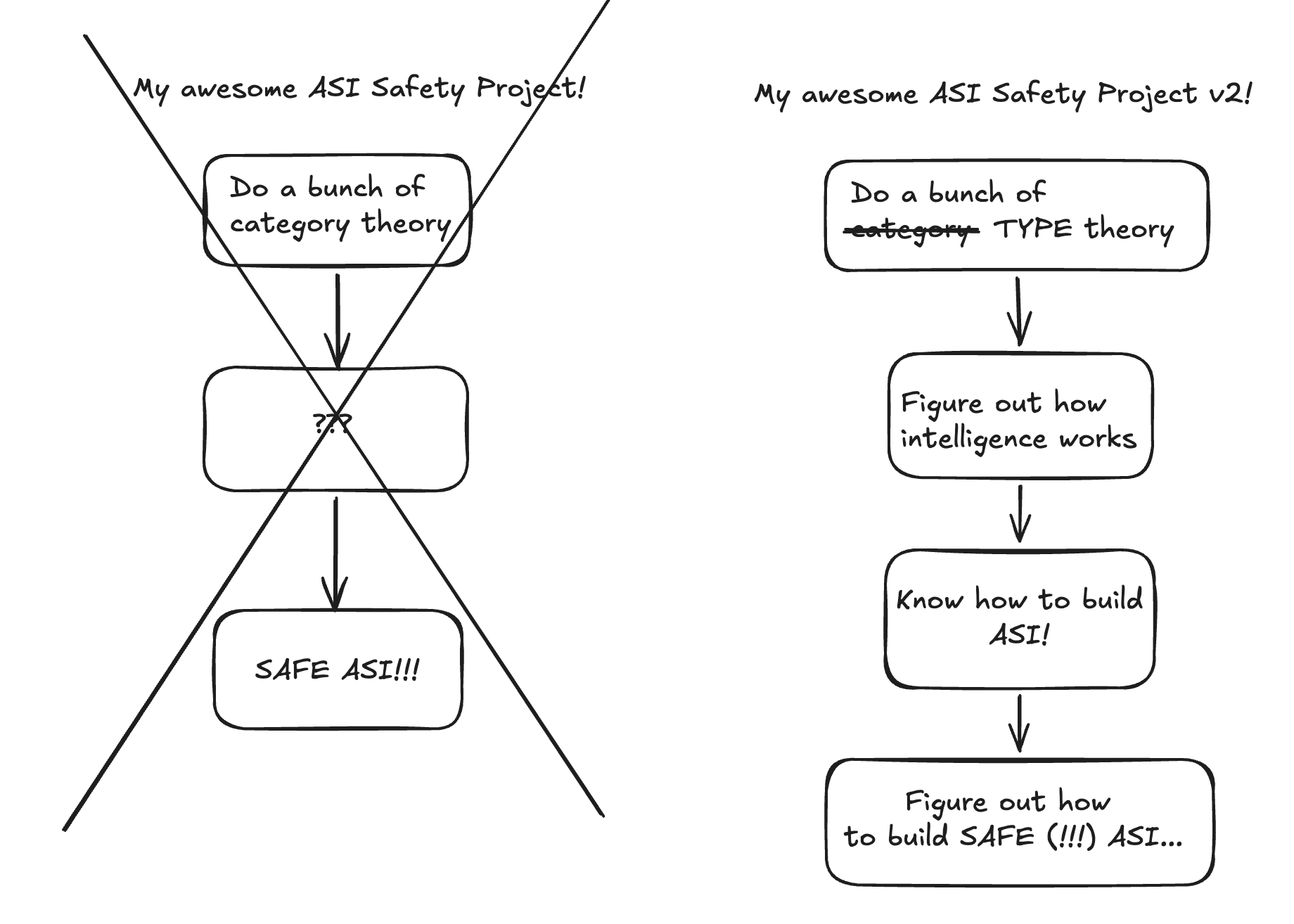
Punchline: On your way to figuring out how to build controllable ASI, you will have figured out how to build unsafe ASI, because unsafe ASI is vastly easier to build than controlled ASI, and is on the same tech path.
You can’t build a controlled ASI without knowing many, MANY things about intelligence and how to build it.
So this then bottlenecks the dual technical problems of “how to find an agenda that results in controllable ASI” and “how to execute on such an agenda” on “even if you had such an agenda, how do you execute it without accidentally, or due to some asshole leaving the project or reading your papers, building unsafe ASI along the way?”
No one I know pursuing various agendas of this type has answers to these questions. And lets be crystal clear: This is the fundamental question any sensible “safe ASI” project needs to answer before even being worth considering.
You would need to either have:
Some absurd level of institutional secrecy and control (e.g. “this research will exclusively be done inside Area 51 and we assassinate everyone who leaves the project and also nuke literally everyone else that tries”)
Complete technical orthogonality (“this research is so radically different from other research that it cannot even in principle be used to build unsafe ASI, only safe ASI”, which is impossible)
A global ban on ASI development and competent enforcement
This means that the primary prerequisite to even considering starting to work on a safe ASI plan is to have a global ASI ban and powerful enforcement already in place.4
I’m assuming you already accept that “unsafe” ASI would be really, really bad. If not, this is not the post for you to read.
In short: If you unilaterally try to build ASI, you are directly and openly threatening the world with violent conquest. This is sometimes called a “pivotal action”, which is code word for “(insanely violent) unilateral action that forces the world into a state I think is good.”
For some hopefully meaningful definition of the word “control”
The good ending is hard-locked behind the bad ending, unless we are afforded the opportunity to spend a very long time working very hard to solve a series of wildly difficult problems.
Do you think there still can be room for people doing conceptual AI safety research (like Agent Foundations), because the ban would get harder to enforce over time and humanity would have to face those problems eventually?
In case we do succeed with the ban, I think we still need to have experts ready to work on alignment as soon as we can, and the only way to create them is to have people do research now.